我们的最新模型 Claude Opus 4.7 现已全面开放使用。
Opus 4.7 在高级软件工程方面较 Opus 4.6 有了显著改进,尤其是在处理最困难的任务时表现更佳。用户反馈称,他们可以放心地将以往需要密切监督的最棘手编码工作交给 Opus 4.7。Opus 4.7 能够严谨且一致地处理复杂、长周期的任务,精确遵循指令,并在汇报结果前设法验证其输出内容。
该模型的视觉能力也大幅提升:它能以更高的分辨率识别图像。在完成专业任务时,它更具品味和创造力,能生成更高质量的界面、幻灯片和文档。此外,尽管其综合能力不及我们最强大的模型 Claude Mythos Preview,但在一系列基准测试中,它的表现均优于 Opus 4.6:
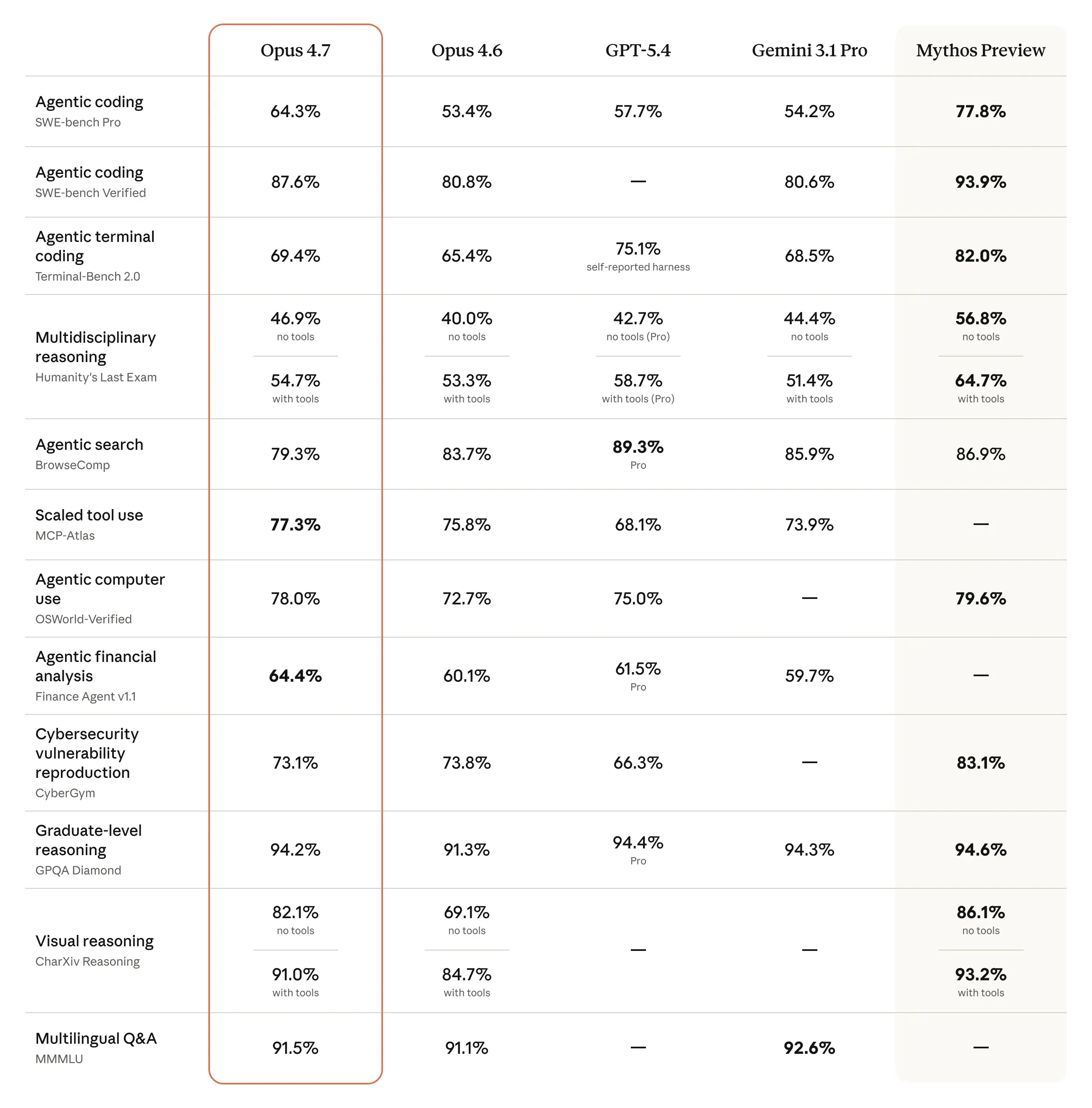
上周,我们发布了 Project Glasswing,重点介绍了 AI 模型在网络安全领域的风险与益处。我们表示将限制 Claude Mythos Preview 的发布范围,并先在能力较弱的模型上测试新的网络防护措施。Opus 4.7 就是首款此类模型:其网络攻防能力不如 Mythos Preview 先进(事实上,在训练过程中,我们尝试了差异化降低这些能力的措施)。我们在发布 Opus 4.7 时配备了安全防护机制,可自动检测并拦截表明存在禁止或高风险网络安全用途的请求。我们从这些安全措施的实际部署中获得的经验,将有助于我们实现最终广泛发布 Mythos 级模型的目标。
希望将 Opus 4.7 用于合法网络安全目的(如漏洞研究、渗透测试和红队演练)的安全专业人士,欢迎加入我们的新 Cyber Verification Program。
Opus 4.7 今天起在所有 Claude 产品以及我们的 API、Amazon Bedrock、Google Cloud 的 Vertex AI 和 Microsoft Foundry 上可用。价格与 Opus 4.6 保持一致:每百万输入 Token 5 美元,每百万输出 Token 25 美元。开发者可以通过 Claude API 使用 claude-opus-4-7。
测试 Claude Opus 4.7
Claude Opus 4.7 从我们的早期访问测试者那里获得了强烈的正面反馈:
在早期测试中,我们看到 Claude Opus 4.7 为我们的开发人员带来了巨大的飞跃潜力。它在规划阶段就能发现自身的逻辑错误并加速执行,远超之前的 Claude 模型。作为一个服务于数百万消费者和企业的大规模金融科技平台,这种速度与精度的结合可能具有变革性:加快开发速度,从而更快地交付客户每天依赖的可信金融解决方案。
Anthropic 已经为编码模型树立了标准,而 Claude Opus 4.7 作为市场上最先进的模型,以有意义的方式进一步推动了这一标准。在我们的内部评估中,它不仅因原始能力脱颖而出,更因其出色地处理现实世界中的异步工作流(自动化、CI/CD 和长周期任务)而备受赞誉。它对问题的思考更深入,并带来更具主见的视角,而不是简单地附和用户。
Claude Opus 4.7 是 Hex 评估过的最强模型。当数据缺失时,它能正确报告,而不是提供看似合理但错误的备选方案;它能抵抗连 Opus 4.6 都会陷入的不一致数据陷阱。它是一个更智能、更高效的 Opus 4.6:低努力程度的 Opus 4.7 大致相当于中等努力程度的 Opus 4.6。
在我们包含 93 个任务的编码基准测试中,Claude Opus 4.7 的解决率比 Opus 4.6 提高了 13%,其中包括四个 Opus 4.6 和 Sonnet 4.6 都无法解决的任务。结合更快的中位延迟和严格的指令遵循能力,这对于复杂、长周期的编码工作流尤为重要。它减少了多步骤任务中的摩擦,使开发人员能够保持心流状态,专注于构建。
基于我们的内部研究代理基准测试,Claude Opus 4.7 拥有我们见过的多步骤工作效率基线中最强的表现。它在我们的六个模块中以 0.715 的分数并列总分第一,并提供了我们测试过的所有模型中最一致的长上下文性能。在最大的模块“通用金融”(General Finance)中,它相比 Opus 4.6 有了显著提升,得分为 0.813(Opus 4.6 为 0.767),同时在群体中展现了最佳的信息披露和数据规范性。而在 Opus 4.6 表现挣扎的演绎逻辑领域,Opus 4.7 表现稳健。
Claude Opus 4.7 扩展了模型调查和完成任务的能力极限。Anthropic 显然针对长周期运行中的持续推理进行了优化,其市场领先的性能证明了这一点。随着工程师从与代理一对一工作转变为并行管理多个代理,这正是解锁新工作流的前沿能力。
我们看到 Claude Opus 4.7 的多模态理解能力有了重大提升,从读取化学结构到解读复杂的技术图表。更高分辨率的支持正在帮助 Solve Intelligence 构建生命科学专利工作流中的一流工具,涵盖从起草和审查到侵权检测和无效性图表绘制的全过程。
Claude Opus 4.7 将 Devin 中的长周期自主性提升到了一个新水平。它能连贯地工作数小时,攻克难题而非放弃,并解锁了一类我们以前无法可靠运行的深度调查工作。
对于 Replit 而言,升级到 Claude Opus 4.7 是一个轻松的决定。对于用户每天的工作,我们观察到它以更低的成本实现了相同的质量——在分析日志和追踪、查找错误以及提出修复建议等任务上更高效、更精准。 personally,我喜欢它在技术讨论中提出反对意见以帮助我做出更好决策的方式。它真的感觉像是一位更好的同事。
Claude Opus 4.7 在 Harvey 的 BigLaw Bench 上展示了强大的实质准确性,在高努力程度下得分 90.9%,在审查表格上的推理校准更好,并且对模糊文档编辑任务的处理明显更智能。它能正确区分转让条款与控制权变更条款,这是一项历来挑战前沿模型的任务。在我们的评估中,实质性内容始终被评为优势:正确、详尽且引用得当。
Claude Opus 4.7 是一款非常令人印象深刻的编码模型,尤其体现在其自主性和更具创造性的推理能力上。在 CursorBench 上,Opus 4.7 的能力有了显著提升,通过率为 70%,而 Opus 4.6 为 58%。
对于复杂的多步骤工作流,Claude Opus 4.7 是一个明显的升级:相比 Opus 4.6,它在更少 Token 消耗和三分之一工具错误率的情况下,性能提升了 14%。它是首个通过我们隐式需求测试的模型,并且能在曾经让 Opus 停滞的工具故障中继续执行。这种可靠性的飞跃让 Notion Agent 感觉像是一位真正的队友。
在我们的评估中,核心编排代理的工具调用和规划准确性出现了两位数的增长。随着用户利用 Hebbia 规划并执行检索、幻灯片创建或文档生成等用例,Claude Opus 4.7 展示了改善这些工作流中代理决策潜力的能力。
在 Rakuten-SWE-Bench 上,Claude Opus 4.7 解决的生产任务数量是 Opus 4.6 的 3 倍,代码质量和测试质量均有两位数增长。这是一个有意义的提升,对于我们团队每天发布的工程工作来说,是一个明确的升级。
对于 CodeRabbit 的代码审查工作负载,Claude Opus 4.7 是我们测试过的最敏锐的模型。召回率提高了超过 10%,在我们最复杂的 PR 中发现了一些最难检测的错误,同时尽管覆盖率增加,精确率仍保持稳定。在我们的测试 harness 上,它比 GPT-5.4 xhigh 稍快,我们正计划在发布时将其用于最繁重的审查工作。
对于 Genspark 的 Super Agent,Claude Opus 4.7 完美契合了三个最重要的生产差异化因素:抗循环性、一致性和优雅的错误恢复。抗循环性最为关键。一个在 18 次查询中有 1 次无限循环的模型会浪费计算资源并阻塞用户。较低的方差意味着生产环境中更少的意外。而且 Opus 4.7 实现了我们测量过的最高的每次工具调用质量比。
Claude Opus 4.7 对 Warp 来说是一个有意义的升级。Opus 4.6 已经是面向开发者的最佳模型之一,而此模型在此基础上 measurable 地更加 thorough。它通过了此前 Claude 模型失败的 Terminal Bench 任务,并解决了一个 Opus 4.6 无法破解的棘手并发 bug。对我们来说,这就是信号。
Claude Opus 4.7 是世界上构建仪表板和数据丰富界面的最佳模型。其设计品味真正令人惊讶——它做出的选择是我真正愿意发布的。它现在是我日常默认使用的模型。
Claude Opus 4.7 是我们在 Quantium 测试过的能力最强的模型。通过我们的专有基准测试解决方案与领先的 AI 模型进行评估,最大的增益出现在最关键的地方:推理深度、结构化问题框架和复杂技术工作。更少的修正、更快的迭代和更强的输出,以解决客户带给我们的最难题。
Claude Opus 4.7 感觉像是智力上的真正飞跃。代码质量明显改善,它剔除了过去堆积的无意义包装函数和回退脚手架,并在过程中自行修复代码。这是自 Sonnet 3.7 过渡到 Claude 4 系列以来,我们见过的最干净的飞跃。
对于构成 XBOW 自主渗透测试核心的计算机使用工作,新的 Claude Opus 4.7 是一个阶跃变化:在我们的视觉敏锐度基准测试中得分为 98.5%,而 Opus 4.6 为 54.5%。我们最大的 Opus 痛点 effectively 消失了,这解锁了它在以前无法使用的一类工作中的应用。
Claude Opus 4.7 对 Vercel 来说是一个坚实的升级,没有任何倒退。它在一次性编码任务上表现非凡,比 Opus 4.6 更正确、更完整,并且对自己的局限性更加诚实。它甚至在开始工作前对系统代码进行证明,这是我们在早期 Claude 模型中未见过的行为。
Claude Opus 4.7 非常强大,在 Factory Droids 的任务成功率上比 Opus 4.6 提升了 10% 到 15%,工具错误更少,验证步骤的后续执行更可靠。它将工作贯彻到底,而不是半途而废,这正是企业工程团队所需要的。
Claude Opus 4.7 自主从头构建了一个完整的 Rust 文本转语音引擎——包括神经模型、SIMD 内核、浏览器演示——然后通过语音识别器反馈其输出,以验证其与 Python 参考实现匹配。数月的高级工程师工作,自主完成。相比 Opus 4.6 的提升显而易见,且代码库已公开。
Claude Opus 4.7 通过了三个此前 Claude 模型无法通过的 TBench 任务,并修复了我们之前最佳模型遗漏的问题,包括一个竞态条件。它在识别真实问题方面表现出强大的精确性,并 surfaced 其他模型要么放弃要么未解决的重要发现。在 Qodo 的真实世界代码审查基准测试中,我们观察到了顶级的精确性。
在 Databricks 的 OfficeQA Pro 上,Claude Opus 4.7 显示出明显更强的文档推理能力,在处理源信息时比 Opus 4.6 少 21% 的错误。在我们的数据代理推理基准测试中,它是用于企业文档分析的表现最佳的 Claude 模型。
对于 Ramp,Claude Opus 4.7 在代理团队工作流中脱颖而出。我们看到了更强的角色忠诚度、指令遵循、协调能力和复杂推理能力,特别是在跨越工具、代码库和调试上下文的工程任务上。与 Opus 4.6 相比,它需要的逐步指导少得多,帮助我们扩展工程团队运行的内部代理工作流。
对于 Bolt 的长周期应用构建工作,Claude Opus 4.7 明显优于 Opus 4.6,在最佳情况下提升高达 10%,且没有出现我们对高度代理化模型预期的倒退。它推高了用户在单次会话中可以交付的内容上限。
以下是我们早期测试 Opus 4.7 的一些亮点和注意事项:
- 指令遵循。Opus 4.7 在遵循指令方面 substantially 更好。有趣的是,这意味着为早期模型编写的提示词有时现在会产生意想不到的结果:以前的模型可能会宽松地解释指令或完全跳过部分指令,而 Opus 4.7 则字面意义上地严格执行指令。用户应相应地重新调整他们的提示词和 harness。
- 改进的多模态支持。Opus 4.7 对高分辨率图像具有更好的视觉能力:它可以接受长边高达 2,576 像素(约 375 万像素)的图像,是此前 Claude 模型的三倍多。这开启了大量依赖精细视觉细节的多模态用途:计算机使用代理读取密集的屏幕截图、从复杂图表中提取数据,以及需要像素级参考的工作。^1
- 现实世界工作。除了在 Finance Agent 评估中获得最先进的分数(见上表)外,我们的内部测试显示,Opus 4.7 比 Opus 4.6 是更有效的金融分析师,能生成严谨的分析和模型、更专业的演示文稿,以及任务间更紧密的集成。Opus 4.7 在 GDPval-AA 上也处于最先进水平,这是一项针对金融、法律和其他领域具有经济价值的知识工作的第三方评估。
- 记忆。Opus 4.7 更擅长使用基于文件系统的记忆。它能在长期、多会话的工作中记住重要笔记,并利用它们进入新的任务,从而减少所需的前置上下文。
下面的图表展示了我们在预发布测试中 across 不同领域的更多评估结果:
安全与对齐
总体而言,Opus 4.7 展现出与 Opus 4.6 相似的安全概况:我们的评估显示,欺骗、阿谀奉承和配合滥用等令人担忧的行为发生率较低。在某些指标上,如诚实度和对恶意“提示注入”攻击的抵抗力,Opus 4.7 优于 Opus 4.6;而在其他方面(如其倾向于就受控物质提供过于详细的减害建议),Opus 4.7 略弱。我们的对齐评估结论是,该模型“大体上对齐良好且值得信赖,尽管其行为并非完全理想”。请注意,根据我们的评估,Mythos Preview 仍然是我们训练过的对齐最好的模型。我们的安全评估在 Claude Opus 4.7 System Card 中有详细讨论。
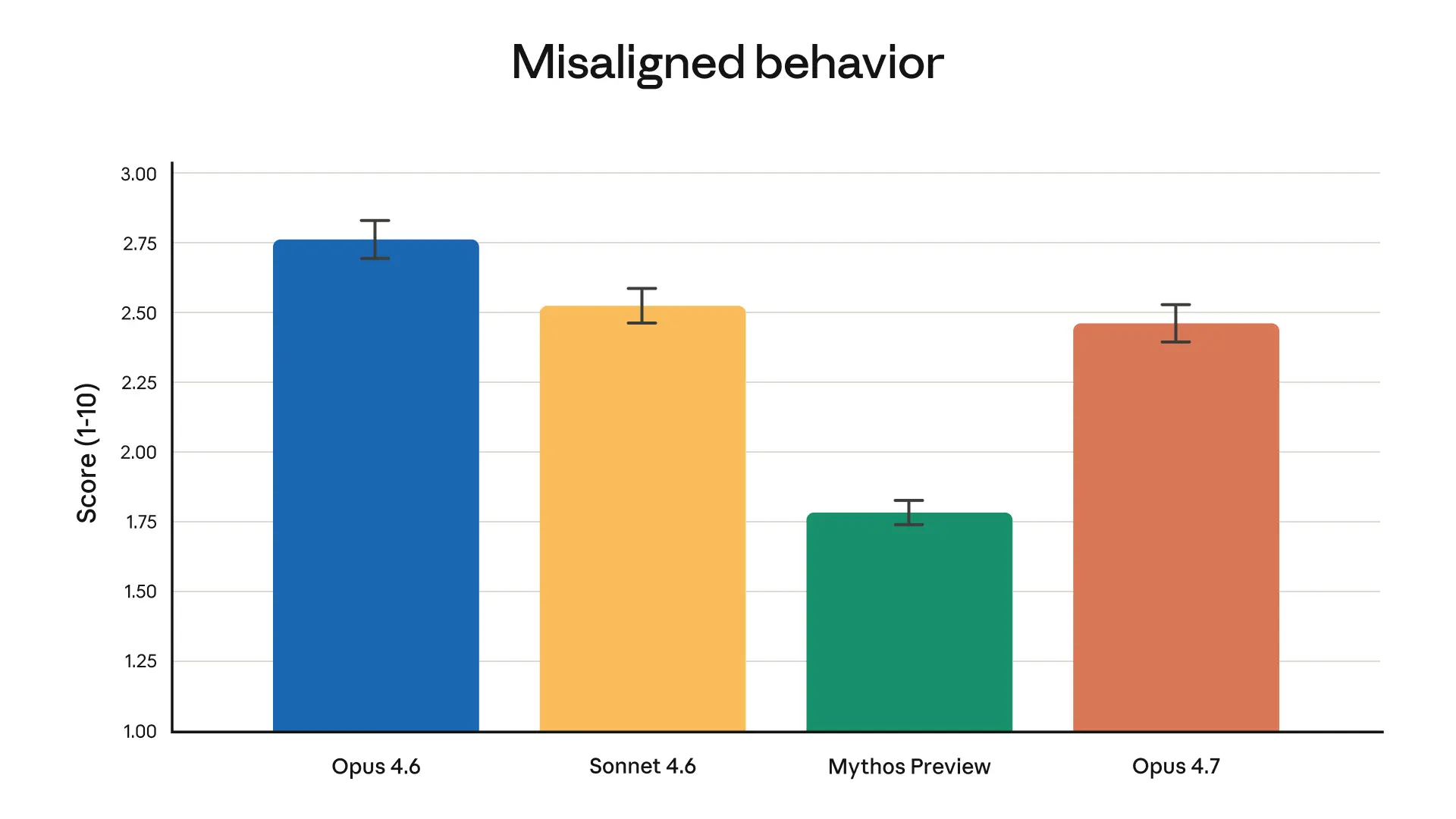
来自我们自动化行为审计的整体不对齐行为得分。在此评估中,Opus 4.7 较 Opus 4.6 和 Sonnet 4.6 有 modest 改进,但 Mythos Preview 仍显示出最低的不对齐行为发生率。
今日同时发布
除了 Claude Opus 4.7 本身,我们还推出了以下更新:
- 更多的努力程度控制:Opus 4.7 引入了一个新的
xhigh(“额外高”)努力程度,介于 high 和 max 之间,让用户能更精细地控制处理难题时推理与延迟之间的权衡。在 Claude Code 中,我们将所有计划的默认努力程度提高到了 xhigh。在测试 Opus 4.7 用于编码和代理用例时,我们建议从 high 或 xhigh 努力程度开始。
- 在 Claude Platform (API) 上:除了支持更高分辨率的图像外,我们还公开发布了任务预算(task budgets)的 beta 版,让开发者能够引导 Claude 的 Token 消耗,以便在长周期运行中优先处理工作。
- 在 Claude Code 中:新的
/ulareview 斜杠命令 会生成一个专用的审查会话,阅读变更并标记出细心审查者会发现的 bug 和设计问题。我们为 Pro 和 Max 版的 Claude Code 用户提供三次免费的 ultrareview 试用机会。此外,我们将 auto mode 扩展到了 Max 用户。Auto mode 是一种新的权限选项,Claude 代表你做出决策,这意味着你可以以更少的中断运行更长的任务——并且比你选择跳过所有权限时的风险更低。
从 Opus 4.6 迁移到 Opus 4.7
Opus 4.7 是 Opus 4.6 的直接升级,但有两个变化值得规划,因为它们会影响 Token 使用量。首先,Opus 4.7 使用了更新的 tokenizer,改进了模型处理文本的方式。权衡之处在于,相同的输入可能会映射到更多的 Token——根据内容类型不同,大约增加 1.0–1.35 倍。其次,Opus 4.7 在较高的努力程度下会进行更多的思考,特别是在代理设置中的后期轮次。这提高了它在难题上的可靠性,但也意味着它会产生更多的输出 Token。
用户可以通过多种方式来控制 Token 使用量:使用 effort 参数、调整任务预算,或提示模型更简洁。在我们自己的测试中,净效果是有利的——如下所示,在内部编码评估中,所有努力程度下的 Token 使用效率均有所提高——但我们建议在实际流量中衡量差异。我们编写了一份 迁移指南,提供了从 Opus 4.6 升级到 Opus 4.7 的进一步建议。
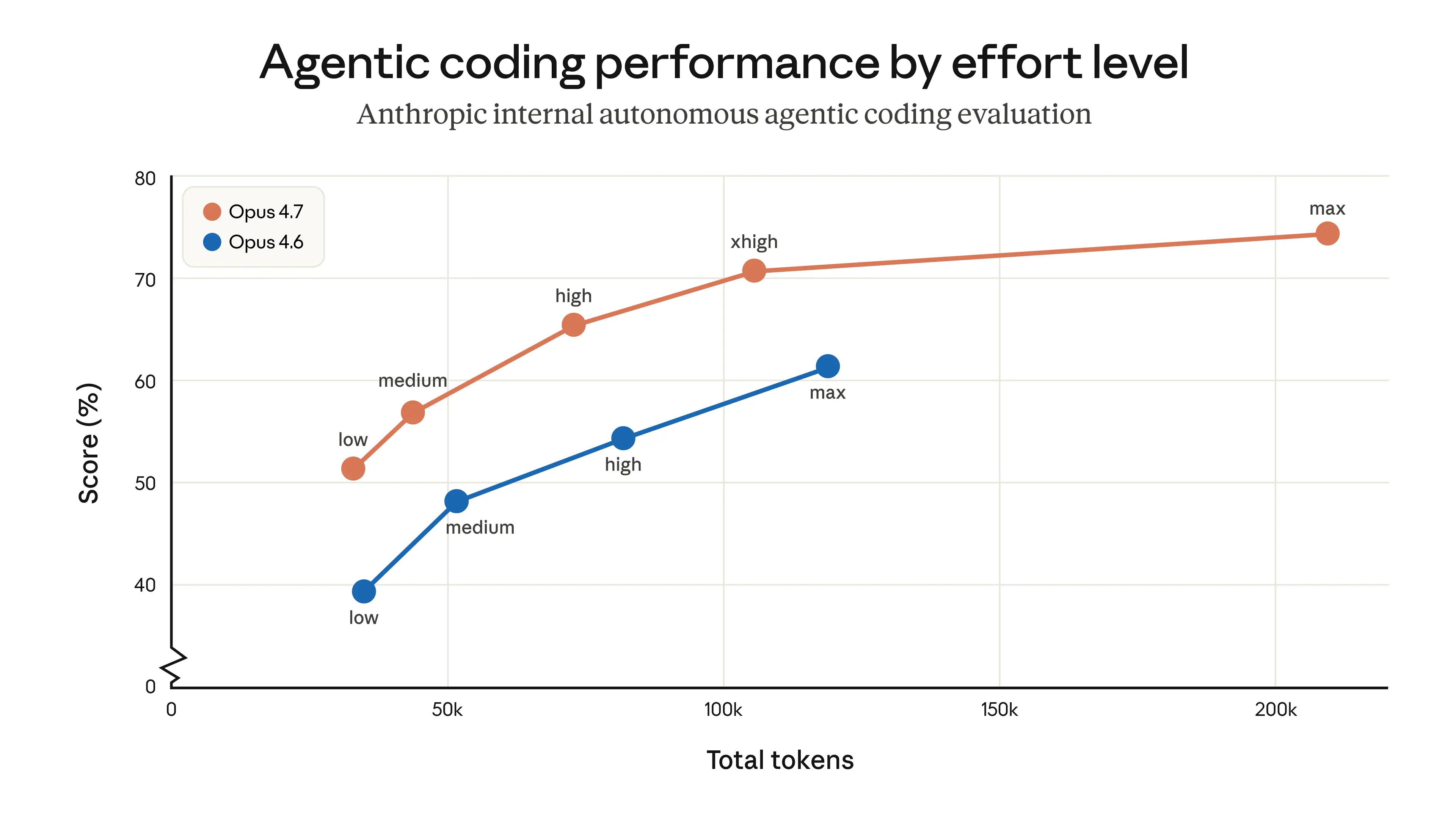
内部代理编码评估中的得分与每个努力程度下 Token 使用量的关系。在此评估中,模型从单个用户提示开始自主工作,结果可能不代表交互式编码中的 Token 使用情况。请参阅 迁移指南 以了解有关调整努力程度的更多信息。
